The client, a Pension Fund firm asked TresVista team to build a standardized model template and model KPI extraction pipeline for investors to start collecting fundamental KPI data, analyzing it, and using it to improve the performance of the investing process. The whole flow created would result in improving modeling quality, providing transparency on key assumptions, and enabling ongoing tracking of forecasting accuracy across time (i.e., Estimates versus Actual). The broader vision of the exercise was also to design a consolidated database that can be further leveraged to build analytics tools that can be used for making data-driven investment decisions.
To create a consolidated bitemporal database that can be leveraged for analytics and tracking of the historical data.
The TresVista team followed the following process:
• Standardized Model Template was created after consultation with Analysts/PMs to collect key financial and operational KPIs
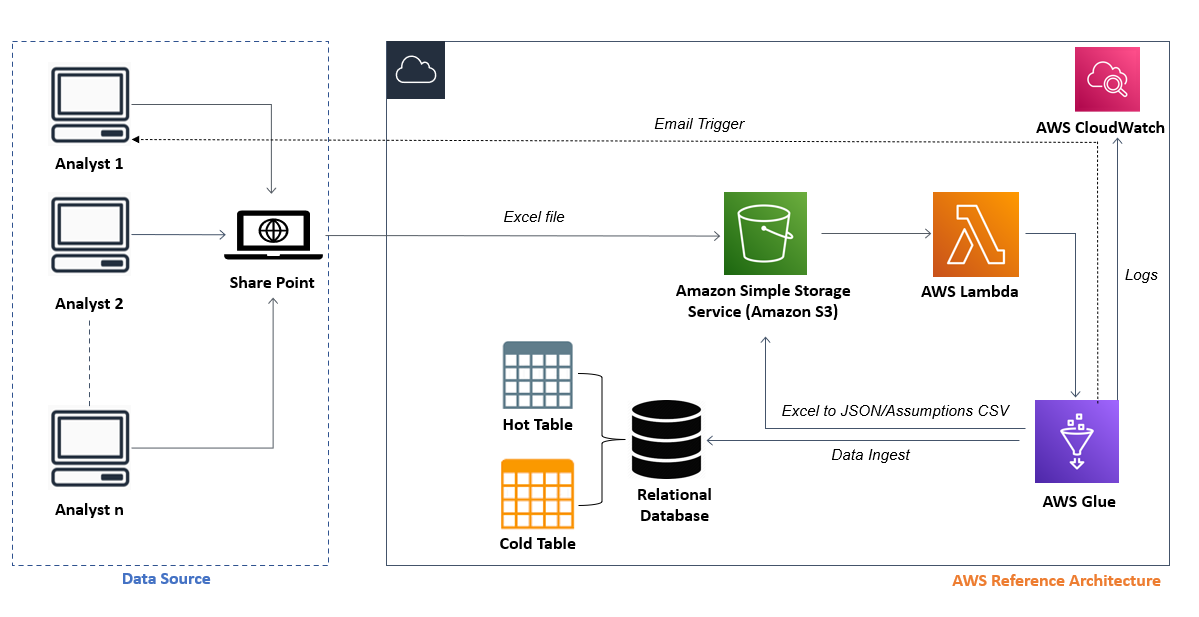
• The user uploaded the model in the SharePoint folder and Power Automate flow transferred the file from SharePoint to Amazon Simple Storage Service (S3) by creating an SFTP server on AWS Transfer Family. Post that, the models transferred to S3 were moved to the transferred folder in the SharePoint
• ETL Process
◦ Whenever a new model is uploaded to the S3 folder, a trigger configured on S3 is invoked that calls a Lambda function
◦ Lambda function is used to call the AWS Glue job to perform the ETL as it provides a serverless data integration service
◦ After the ETL was completed, the transformed data was saved in JSON format, and stored in a separate folder of the S3 bucket. The same transformed data was also uploaded to the bitemporal database, and the audit trail could be viewed in the database
◦ SMTP library in Python was used to trigger an email to the user, which provided details on the status of model submission along with possible inconsistencies in the model
The major hurdles faced by the TresVista team were:
• Learning nuances of Cloud platform Amazon Web Service (AWS) from scratch and implementing it within the designated deadline was one of the hurdles that the team faced
• Understanding the user behavior during the User Application Testing phase and proactively solving the issues that they may face was another challenge
• Understanding the financial model of the client and incorporating its nuances in the ETL code
• Over time the code became huge so tracking and managing the changes/modifications became a challenge
• Constant changes in the model also led to back-and-forth between the teams
The team overcame these hurdles by undertaking upskilling courses and reading AWS documentations to learn more about AWS. They proactively spent time to understand user behavior and incorporating the way they would interact with the tool to the code to create a good user experience. For example, the team observed that the users were not filling in required fields like Investment Domain in the model, so they provided them instructions in the email triggers to do so instead of relying on them to remember. The code was later stored in a GitHub repository setup in the client’s GitHub domain for tracking/maintaining changes in the code. The TresVista team also documented changes to be made on One Note so that the team does not lose track of them.
• Bitemporal database was created to track modeling quality and forecasting accuracy
• The whole data ingestion flow is automated and hosted on AWS resulting in minimum manual intervention from the user
• Automated email triggers are sent to the user highlighting the inconsistencies present in the model and guiding the user to take remedial actions to correct them
• The consolidated database created can be used to perform various analysis: Performing competitor analysis or tracking the sector landscape; Comparing the forecast with the actual numbers of a company over time; Tracking the changes in Analyst forecast over time







